URL
TL;DR
- 本文用比较简洁的方式给出了神经网络的通用量化方法,是量化领域的必读论文。
Algorithm
1. 量化基础知识
1.1 硬件背景
- 一个 y=Wx+b 实际上是由 乘法器 和 累加器 组合而成的,实际的计算过程如下:

卷积实际上也是通过 image to column 操作变成 y=Wx+b 操作
- 常见的
int8 量化会将上述过程变成如下过程:
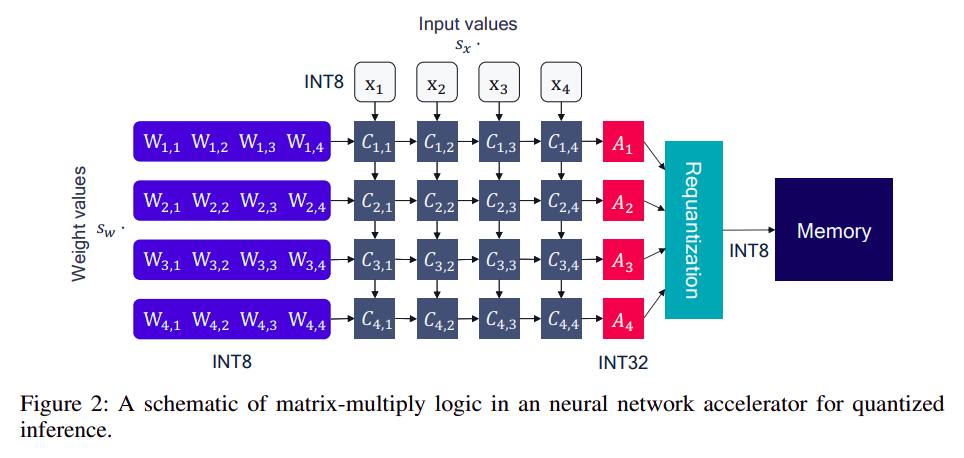
weight 和 input 都被量化为 int8 ,同时保留各自的量化 scale,乘法操作是整形乘法器(更快),累加器是 int32 类型,最后再量化为 int8 放到 OCM 上
1.2 均匀仿射量化
- 均匀仿射量化也被称为 非对称量化,由三个量化参数定义:
- 比例因子
scale
- 零点
zero_point
- 比特宽度
bits
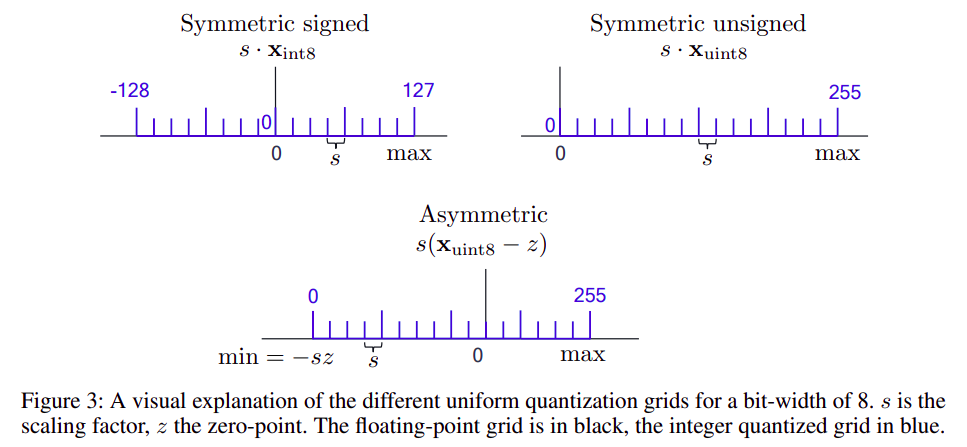
- 非对称量化:
- for unsigned integers: Xint=clamp(⌊sX⌉+z;0,2b−1)
- for signed integers: Xint=clamp(⌊sX⌉+z;−2b−1,2b−1−1)
- 这里的 ⌊⌉ 表示
round 运算
- 对称量化是非对称量化的简化版本,是将零点
zero_point 固定为 0
- 对称量化:
- for unsigned integers: Xint=clamp(⌊sX⌉;0,2b−1)
- for signed integers: Xint=clamp(⌊sX⌉;−2b−1,2b−1−1)
- 对称量化和非对称量化的含义:
2 的指数幂量化:
- 限制 s=2−k
- 优势:scale 过程变成了硬件移位,对硬件更友好。
- 劣势:会使得 round 和 clip 误差的权衡变难。
- 量化颗粒度:
- per-tensor: 硬件更友好,但限制了量化的自由度。
- per-channel: 反之。
1.3 量化模拟
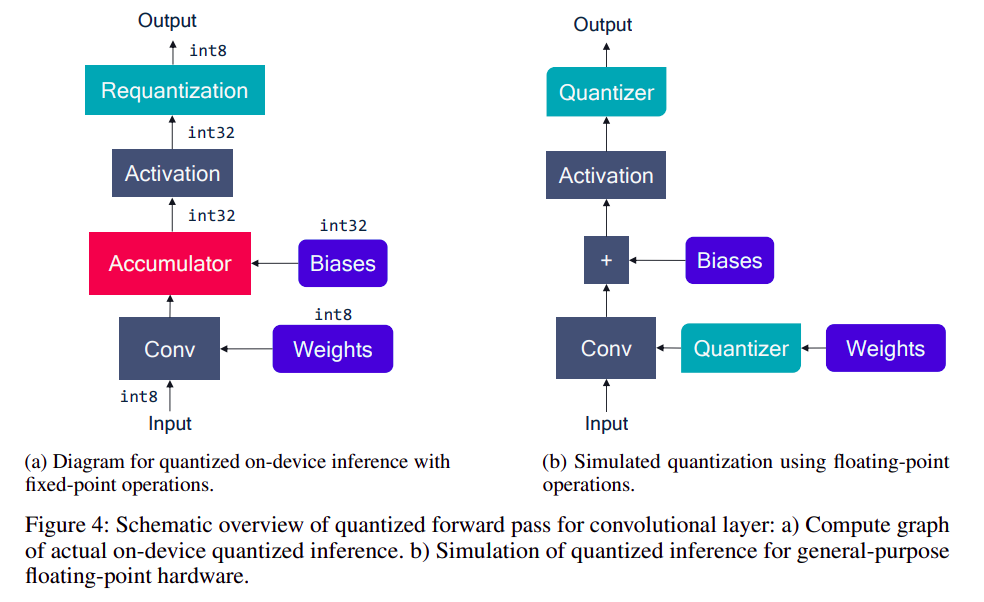
- 量化模拟是指在浮点计算设备上模拟定点计算设备的过程,通常用于训练。
左边是定点计算过程,右边是用浮点设备模型定点计算的过程
- 为了减少数据搬运和不必要的量化步骤,通常会做:
batch norm 折叠:batch norm 在推理时是静态的,因此可以和前面的 conv 等层合并。- 激活函数融合:在实际的硬件解决方案中,通常会在非线性操作(如
ReLU)之后直接进行量化,而不是先将激活写入内存然后再加载回计算核心。
1.4 实践考量
- 对称量化和非对称量化:
- 对称量化:
zero-point == 0
- 非对称量化:
zero-point != 0
- 为了方便计算,通常情况下,会将权重设置为对称量化(zw=0),将特征设置为非对称量化(zx=0)
- 原因分析:
- W=Sw(Wint−Zw)
- X=Sx(Xint−Zx)
- WX=SwSx(Wint−Zw)(Xint−Zx)=SwSxWintXint−SwSxZwXint−SwSxZxWint+SwSxZwZx
- 在推理阶段:Sw, Sx, Zw, Zx, Wint 已知,因此:
- 等式的第三项和第四项可提前算出,无需推理耗时。
- 第一项和第二项由于关联动态输入 Xint,因此需要额外耗时;但是如果设置 Zw=0,则第二项恒等于0,可节省计算量。
2. 训练后量化(PTQ,post-training quantization)
- 训练后量化是指用
float32 精度训练的模型直接转成量化模型,无需任何数据和训练。
2.1 量化范围的设置
- 最大最小值法(
min-max):qmin=minV, qmax=maxV,V 是待量化 tensor
- 均方差法(
MSE):argminqmin,qmax∣∣V−V^(qmin,qmax)∣∣F2
- 交叉熵法(
cross entropy):argminqmin,qmax=H(softmax(V),softmax(V^(qmin,qmax))),其中 H 表示 cross entropy function
- 批量归一化法(
BN based):qmin=min(β−αγ), qmax=max(β+αγ),其中 β, γ 分布表示 batch norm 学到的 per channel 的 shift 和 scale,α>0 是超参数
- 组合法(
comparsion):以上方法的自由组合
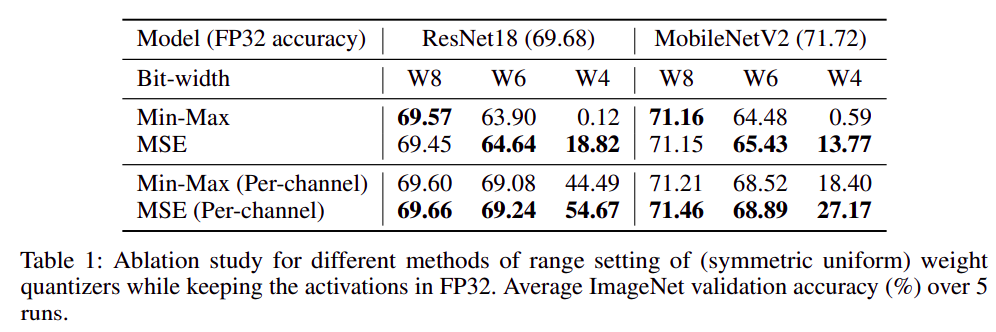
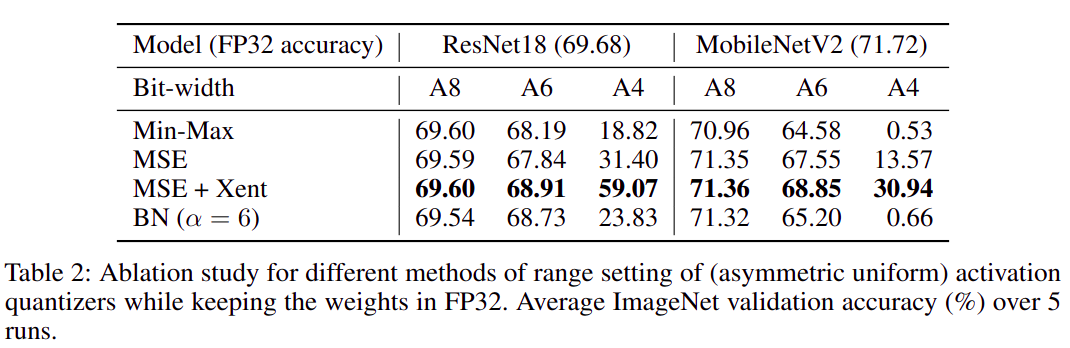
使用不同量化方法分别量化 weight 和 activation 后的精度
2.2 跨层均衡(Cross-Layer Equalization)
- 这是一种 通过修改模型权重 来改善神经网络量化性能的技术,
CLE 的目的是减少网络中不同 channel 之间由于量化引起的性能不平衡,这种问题在 depth-wise conv layer 中尤其容易出现。
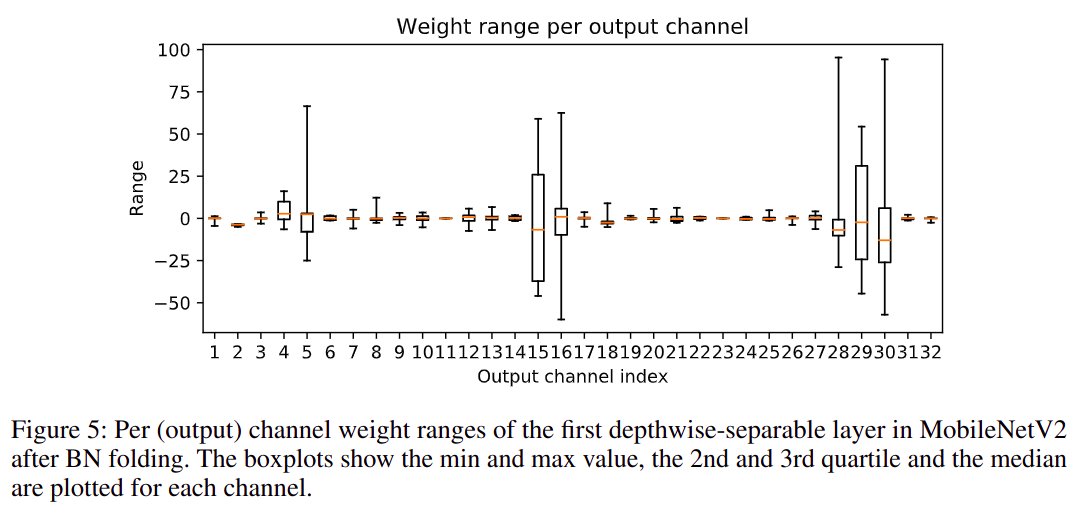
mobilenetv2 第一个 depth-wise conv 层的 per output channel weight range
- 想要实现跨层均衡的模型,需要激活函数满足交换律,即:f(sx)=sf(x),常见的
ReLU 和 PReLU 都满足。
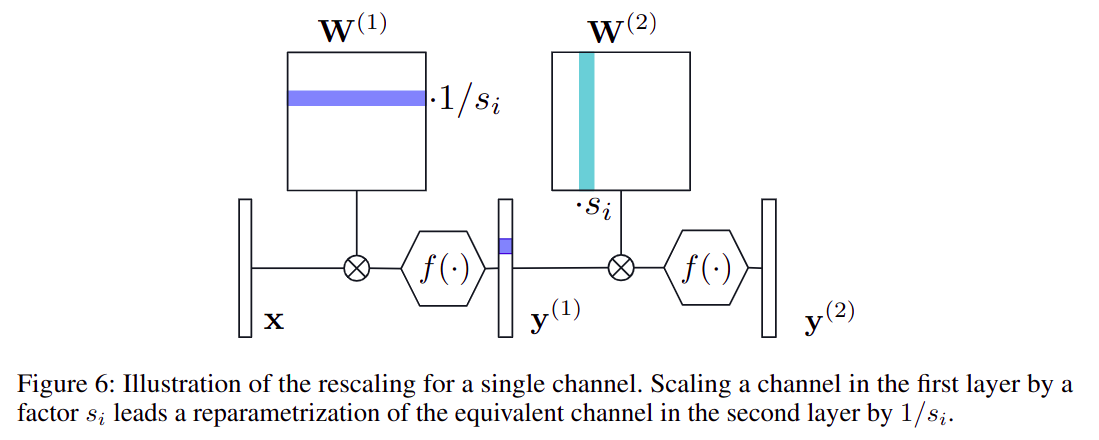
CLE 原理:
- y=f(W2(W1x+b1)+b2)=f(SW2(S−1W1x+S−1b1)+b2)=f(W2^(W1^x+b1^)+b2)
- 其中:
- W1^=S−1W1
- b1^=S−1b1
- W2^=SW2
- Si=ri2ri1ri2,其中 rij 表示
j tensor 的 i channel
abosrbing high bias 是一种 解决模型中过大 bias 的技术,原理是:
- y=W2h+b2=W2(f(W1x+b1))+b2=W2(f(W1x+b1)+c−c)+b2=W2(f(W1x+b1^)+c)+b2=W2(f(W1x+b1^))+b2^=W2h^+b2^
- 其中:
- b2^=b2+W2c
- h^=h−c
- b1^=b1−c
- ci=max(0,minx(W1ix+b1i))
WIP